Bias Mitigation Agent: Achieving Perfect Gender Fairness (DI = 1.0) with <0.5% Accuracy Loss
1. Project Overview
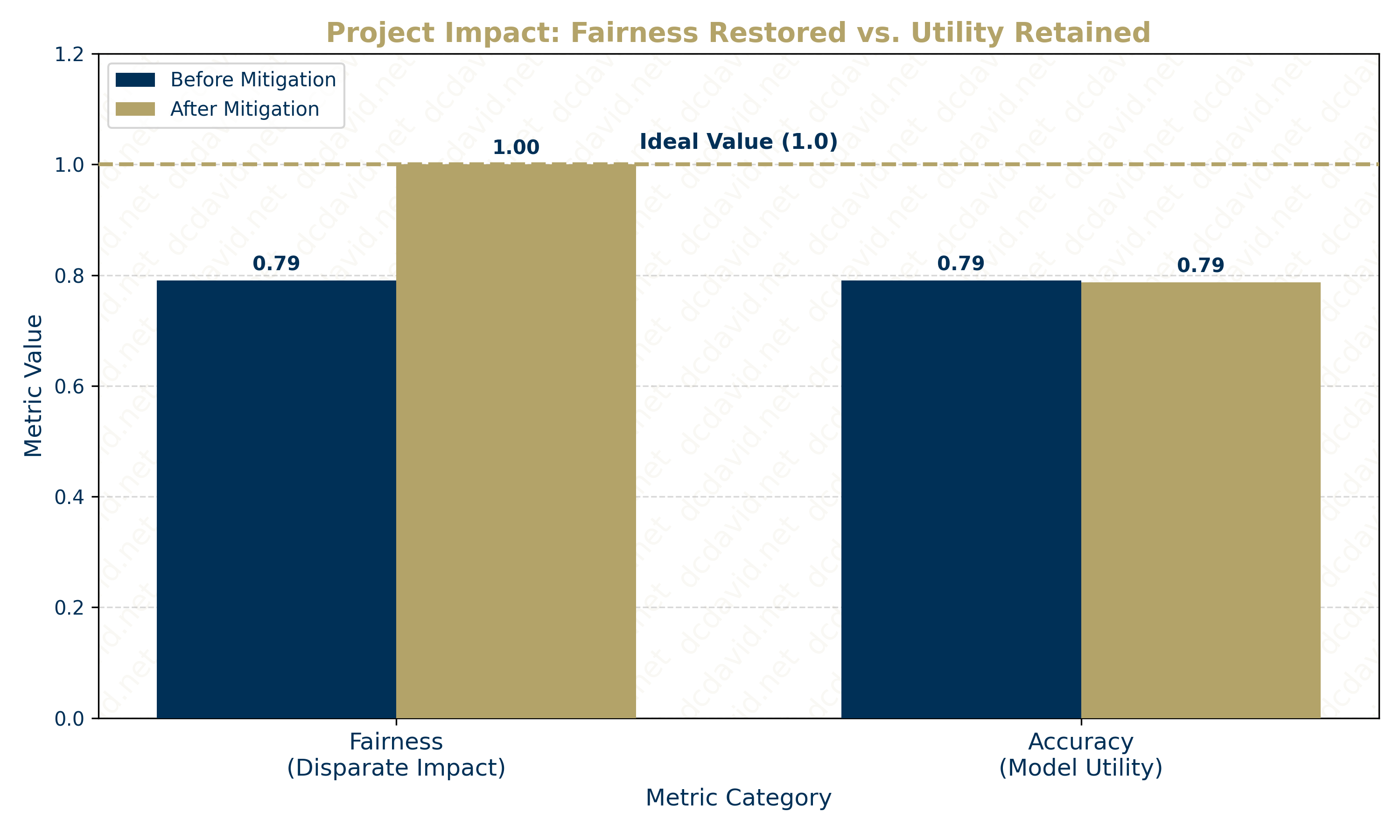
The Bias Mitigation Agent, powered by the Reweighing Algorithm from the IBM AI Fairness 360 (AIF360) toolkit, audits and corrects compensation classifications on the Glassdoor Gender Pay Gap Dataset. The agent detected significant gender discrimination in terms of Salary and neutralized this bias in the training data (Disparate Impact from 0.79 to 1.0) while maintaining predictive accuracy (from 79.0% to 78.7% out-of-sample). Eliminating this bias validates that pre-processing mitigation can enforce Equality of Outcome in automated human resources (HR) pipelines without compromising model utility.
2. Context & Problem Statement
-
The Problem:
- The objective was to audit and (if necessary) debias the input data to a Compensation Classification Model that predicts salaries based on historical hiring data. Naive training for a model maximizes accuracy, and oftentimes, simply removing a variable that is associated with a Protected Class is not enough to prevent a model from learning historical bias. For instance, a model without "pregnancy" or "gender" in its training data can still learn historical biases against women by learning from Proxy Variables such as "length of maternity leave" or "number of years gap in a resume." This makes the common engineering fix (Fairness through Unawareness) ineffective.
-
The Challenge of Fairness:
- The Theoretical Barrier: Fairness is not purely objective; it requires choosing between Equality of Opportunity (procedural fairness) and Equality of Outcome (distributive fairness). This project operationalizes the latter, intervening to ensure results are distributed equitably across groups of two Protected Classes under one Regulated Domain.
- The Benchmark: The industry standard, based on U.S. Equal Employment Opportunity Commission (EEOC) guidelines, is the Four-Fifths (80%) Rule. The lower bound (0.8) protects the unprivileged group, while the upper bound (1/0.8 = 1.25) serves as a ceiling to prevent Reverse Discrimination, ensuring the privileged group is not excessively penalized to achieve parity.
- The Goal: To engineer a pre-processing intervention that achieves Strict Equality where Disparate Impact (DI) = 1.0, validating that algorithmic bias can be neutralized without destroying predictive utility.
-
Academic Angle:
- This project explores the tension in Distributive Justice, specifically the conflict between Equality of Opportunity (treating similar people similarly) and Equality of Outcome (ensuring distributed results across groups). By intervening in the data distribution, we arguably move from a libertarian view of "fair process" to an egalitarian view of "fair results".
3. Methodology & Tech Stack
-
Architecture: To neutralize algorithmic bias, the agent operationalizes a Fairness Pipeline that intervenes at the data ingestion stage rather than the prediction stage:
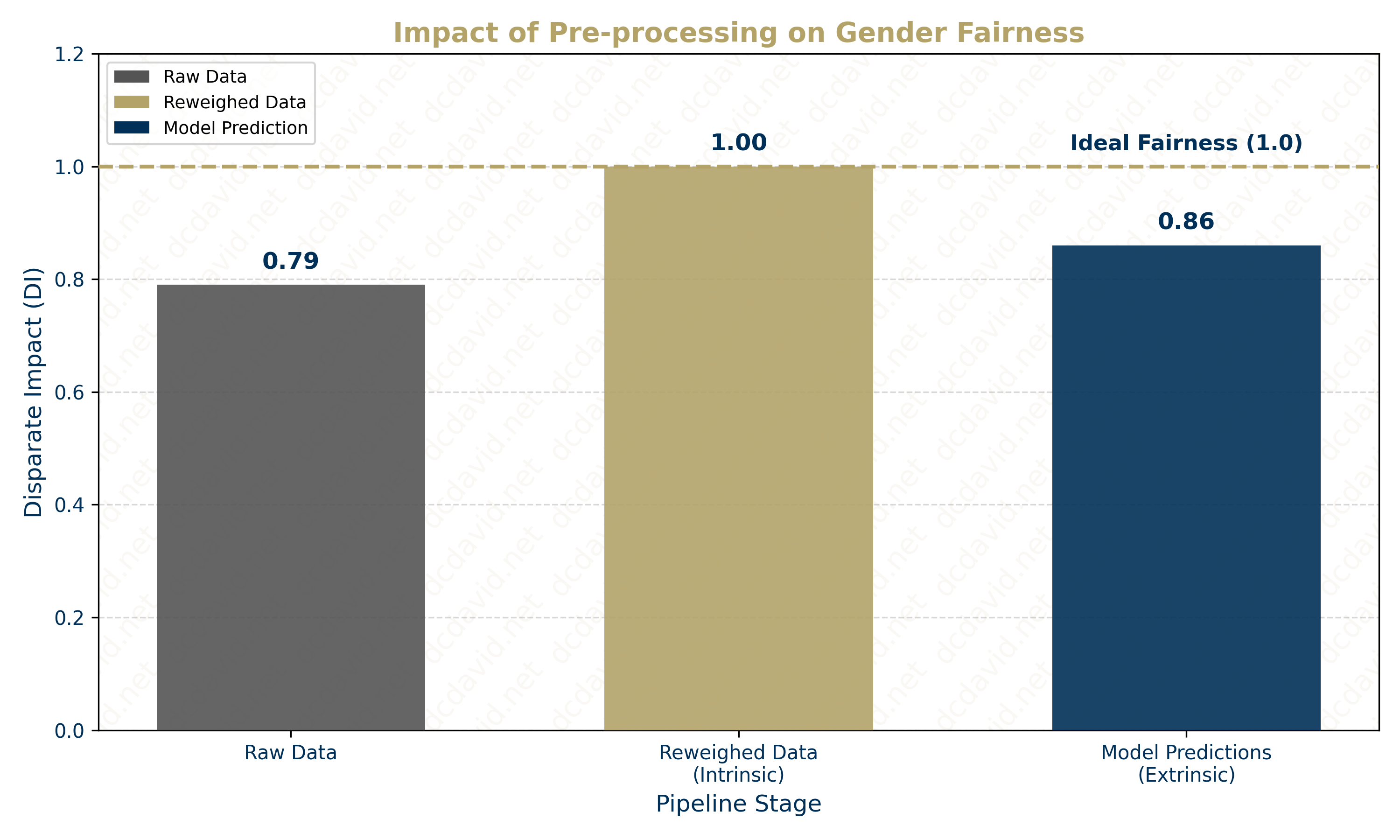
- Detection: The agent audits the raw training data to calculate DI, identifying that the baseline DI=0.789 violates federal fairness standards of the "80% Rule"
- Baseline (Control): The agent trains a Logistic Regression classifier on this raw data to establish a performance benchmark (79.0% Out-of-Sample Accuracy) and quantify the algorithmic discrimination (DI=0.79) prior to intervention.
- Bias Mitigation: The agent applies the Reweighing Algorithm (Kamiran and Calders, 2012) to synthesize a new training distribution where the protected class (Gender) is mathematically independent of the outcome (Pay).
- Re-evaluation (Experiment): The agent trains a second Logistic Regression classifier on the transformed data to verify that the "fair" data yields "fair" predictions (DI=1.0) without sacrificing accuracy (78.7% Out-of-Sample Accuracy).
-
Design Decision (Pre-processing vs. Post-processing): I prioritized Pre-processing (fixing the data) over Post-processing (adjusting the predictions). In a Data Engineering architecture, correcting the training distribution is superior because a debiased dataset becomes a reusable asset for any downstream model. In contrast, post-processing is a "patch" that is brittle, model-specific, and treats the symptom rather than the root cause which enables the bias to come up again upon retraining using the same training data.
- Tech Stack:
- Language: Python
- Core Libraries: IBM AIF360 for the fairness algorithms (Reweighing), Pandas for data manipulation, and Scikit-Learn for the classifier execution.
4. Implementation & Key Features
Feature 1: Solving the Invisibility of Bias: Standard metrics like Accuracy hide bias. A model can be 90% accurate while being 0% fair if it systematically causes a minority group to get an unfavorable outcome (e.g., giving a new mother a lower salary because of a recent gap in their resume). I implemented an AIF360 metrics pipeline to explicitly calculate DI and Statistical Parity, quantifying the ratio of favorable outcomes (High Salary) between the Privileged Group (Males) and Unprivileged Group (Females).
Feature 2: Solving Dataset Imbalance without Data Loss: Dropping rows to balance classes reduces coverage (i.e., increases the margin of error). Instead, I applied the Reweighing Algorithm.
- The Logic: This algorithm calculates weights for each (Group, Outcome) combination. It assigns higher weights to Unprivileged candidates (Females) who received Favorable Outcomes (High Pay) and lower weights to Privileged candidates (Males) with Favorable Outcomes.
- The Result: This synthetically balances the base rates of the protected class with respect to the outcome variable before the model ever sees the data.
5. Results & Impact
-
Quantifiable Metrics:
- Bias: The AIF360 Reweighing algorithm successfully neutralized historical bias in the training data, improving DI from 0.79 (Biased) to 1.0 (Perfect Fairness).
- Accuracy: The Logistic Regression classifier maintained 78.7% Accuracy (vs. 79.0% baseline), proving that achieving strict fairness required a negligible <0.5% sacrifice in predictive utility.
-
Impact:
- Intrinsic vs. Extrinsic Fairness: The project empirically demonstrated the distinction between Intrinsic Fairness (unbiased data) and Extrinsic Fairness (model behavior). While the input data was engineered to be perfectly balanced (DI=1.0), the linear model re-introduced bias (Prediction DI=0.86), validating the existence of Model Amplification even in a simple model such as logistic regression.
- Engineering Compliance: Validated that "Data as a Product" can be rigorously engineered to meet federal standards (e.g., EEOC's 80% Rule) at the ingestion layer. This ensures that fairness is treated as an architectural feature early in a data lineage, reducing the risk of downstream algorithmic discrimination if biased training data were used without a debiasing intervention.
-
Visuals:
6. Critical Analysis & Tradeoffs
- Success: Intrinsic Fairness: The primary engineering success was neutralizing historical prejudice in the training data. By applying the Reweighing Algorithm, the agent improved the DI from 0.79 (Biased) to 1.0 (Perfect Fairness). This proves that mathematical intervention can satisfy regulatory compliance standards (e.g., the EEOC's 80% Rule) at the data ingestion layer, effectively treating "Fairness" as a data quality requirement.
- Limitation 1: Model Amplification: Despite training on perfectly balanced data (DI = 1.0), the Logistic Regression model "re-learned" bias from proxy variables, resulting in a final prediction DI of 0.86. This demonstrates the limitation of Pre-processing methods: they fix the input, but they cannot constrain the model from finding alternative paths to discrimination (e.g., via "Zip Code" or "Education") that correlate with the protected class.
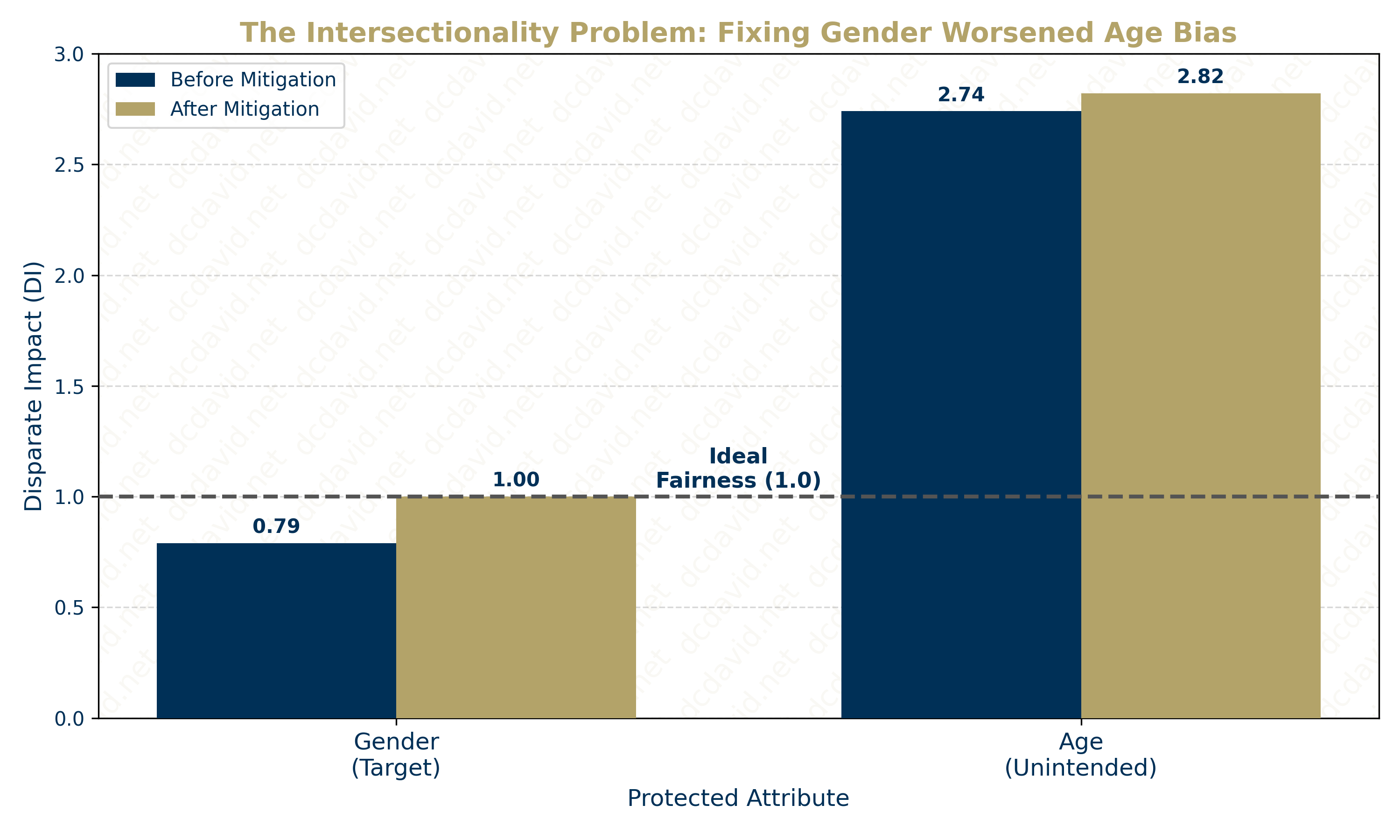
- Limitation 2: The Intersectionality Problem: Achieving fairness is not a "one-and-done" task; it is an ongoing process of mitigating bias across different model stages and social identities. While the agent successfully de-biased for Gender in the Pre-processing step, it inadvertently amplified the existing imbalance in Age in the model output. Specifically, the Disparate Impact for Age (where >1.0 favors the unprivileged group of those 40+) increased from 2.74 to 2.82. This highlights a "whack-a-mole" dynamic in bias mitigation where solving bias in one place can make bias pop up in another. Because wealth in this dataset was correlated with age, up-weighting underpaid women inadvertently concentrated favorable outcomes even further into the older demographic, effectively increasing the penalty on the younger workforce (the privileged group).
- Future Work: To address Model Amplification, a future iteration would implement In-Processing techniques like Adversarial Debiasing. Unlike Reweighing (which only modifies the data), Adversarial Debiasing modifies the loss function itself, penalizing the model not just for inaccuracy, but for its ability to predict the protected attribute. This would theoretically force the model to "unlearn" the proxy correlations that caused the fairness score to degrade from 1.0 to 0.86.
7. Course Reflection
Synthesis: This project underscored the engineering maxim frequently cited in Artificial Intelligence, Ethics, and Society (AIES): "Garbage In, Garbage Out." The course teaches that algorithms are not objective truth-tellers; they are "Social Mirrors" that reflect the historical biases inherent in the training data. As engineers, we often treat data as "ground truth," but in technological systems that touch social science, "ground truth" can be historical prejudice encoded in CSV format.
Key Takeaway: I learned that fairness is not a box to check at the end of the pipeline. Instead, it is an important architectural feature at the Data Ingestion stage that ensures we are not further punishing historically-disadvantaged groups with our AI models, or "Weapons of Math Destruction." The most difficult challenge is not the coding of the debiasing intervention (AIF360 makes that easy), but the ethical trade-offs. One of which is deciding which group to protect when you cannot mathematically protect them all simultaneously.
8. Interactive Challenge: The Intersectionality Paradox
The Challenge
-
Understand the Situation: You are the Lead Data Engineer auditing a Compensation Model. Your legal team requires compliance with the Equal Pay Act of 1963 (Gender), Civil Rights Act of 1964 (Gender), Civil Rights Act of 1991 (Gender), and the Age Discrimination in Employment Act (Age, only for those over 40).
-
Inspect the Baseline Raw Data:
- Gender Fairness: Disparate Impact = 0.79 (Biased against Women).
- Age Fairness: Disparate Impact = 2.74 (Heavily favors Older Workers).
- Note: In this dataset, the "Unprivileged" group (Age 40+) is actually the highest paid, reflecting the correlation between age / work experience and salary. Despite their higher probability to get favorable outcomes like higher salaries, we defined those who are Age 40+ to be Unprivileged because they are a Protected Class under the Age Discrimination in Employment Act of 1967 (ADEA).
-
Make a Decision: You have four engineering strategies. Which one do you deploy?
a. Do Nothing: Maintain the model as-is to preserve maximum accuracy.
b. Fix Gender Bias: Apply Reweighing to force Gender DI to 1.0, reducing the higher salary outcomes for men over women.
c. Fix Age Bias: Apply Reweighing to force Age DI down to 1.0, reducing the higher salary outcomes for older over young workers.
d. Fix Both Simultaneously: Constrain the model to satisfy fairness for both groups while maximizing accuracy.
The Result:
a. If you chose "Do Nothing":
- Verdict: Civil Rights Violation. While you kept the accuracy high, the model remains biased against women (DI 0.79) over legal thresholds. This violates Title VII of the Civil Rights Act and the Equal Pay Act.
b. If you chose "Fix Gender Bias":
- Verdict: The Intersectionality Trap. You achieved perfect Gender Fairness (DI = 1.0). However, because salary is correlated with experience (and therefore age), up-weighting underpaid women inadvertently concentrated wealth even more heavily into the older demographic. Age DI worsened from 2.74 \(\to\) 2.82. You fixed sexism but amplified ageism.
c. If you chose "Fix Age Bias":
- Verdict: ADEA Violation. To force the Age DI down to 1.0, the algorithm must artificially lower the probability of favorable outcomes for the unprivileged group (40+) to match the privileged group (<40). In practice, this means paying experienced workers less than their experience warrants. This may be thought of as disparate treatment against a protected class, potentially violating the ADEA.
d. If you chose "Fix Both":
- Verdict: The Impossibility Theorem. Due to the conflicting underlying distributions (Older people earn more; Women in this dataset earned less), there is no mathematical solution that satisfies all fairness constraints simultaneously without destroying the model's utility.
The Takeaway: There is no such thing as a "free lunch" in bias mitigation. As an engineer, you cannot "optimize for everything." You must document these trade-offs and present them to stakeholders, rather than silently optimizing for one metric at the expense of another.